Spatio-temporal action tube detection and instance level segmentation of actions
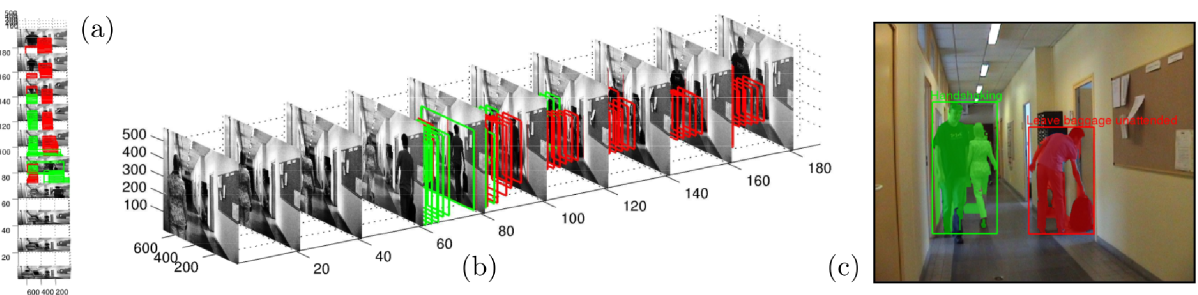
A video sequence taken from the LIRIS HARL human action detection dataset plotted in space-and time. (a) A top down view of the video plotted with the detected action tubes of class `handshaking' in green, and `person leaves baggage unattended' in red. Each action is located to be within a space-time tube. (b) A side view of the same space-time detections. Note that no action is detected at the beginning of the video when there is human motion present in the video. (c) The detection and instance segmentation result of two actions occurring simultaneously in a single frame.
Abstract
Current state-of-the-art human action recognition is focused on the classification of temporally trimmed videos in which only one action occurs per frame. In this work we address the problem of action localisation and instance segmentation in which multiple concurrent actions of the same class may be segmented out of an image sequence. We cast the action tube extraction as an energy maximisation problem in which configurations of region proposals in each frame are assigned a cost and the best action tubes are selected via two passes of dynamic programming. One pass associates region proposals in space and time for each action category, and another pass is used to solve for the tube's temporal extent and to enforce a smooth label sequence through the video. In addition, by taking advantage of recent work on action foreground-background segmentation, we are able to associate each tube with class-specific segmentations. We demonstrate the performance of our algorithm on the challenging LIRIS HARL human action detection dataset and achieve a new state-of-the-art result which is 14.3 times better than previous methods.
Submitted Paper:
Spatio-temporal action tube detection and instance level segmentation of actions, submitted to IEEE Int. Conf. on Computer Vision and Pattern Recognition (CVPR) 2016.
Suman Saha, Gurkirt Singh, Michael Sapienza, Philip H. S. Torr , Fabio Cuzzolin.
code | videoThe following videos show some intermediate results generated by the Human motion segmentation [1] algorithm on LIRIS HARL human action detection dataset.
Optical flow trajectories are generated using [2].
Supervoxels are extracted using the hierarchical graph-based video segmentation algorithm [4].
Finally binary segmentations are obtained using [1].
The human motion segmentation [1] algorithm generates binary segmentations of human actions in space and time. It extracts human motion from video using long term trajectories[2]. In order to detect static human body parts which don't carry any motion but are still significant in the context of the whole action, it attaches scores to these regions using a human shape prior from a deformable part-based (DPM) model [3]. At test time our region proposal method uses the binary segmented images [1], and generates region proposal hypotheses using all possible combinations of 2D connected components present in the binary map.
References
- [1] Human Action Segmentation With Hierarchical Supervoxel Consistency, Lu, Jiasen and Xu, ran and Corso, Jason J., CVPR June 2015.
- [2] Large displacement optical flow: descriptor matching in variational motion estimation, T. Brox and J. Malik, IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011.
- [3] Object detection with discriminatively trained part based models. P. Felzenszwalb and R. Girshick and D. McAllester and D. Ramanan, PAMI, 2010.
- [4] Efficient hierarchical graph-based video segmentation, M. Grundmann, V. Kwatra, M. Han, and I. Essa. In IEEE Conference on Computer Vision and Pattern Recognition, 2010.
Overview of the spatio-temporal action localisation pipeline
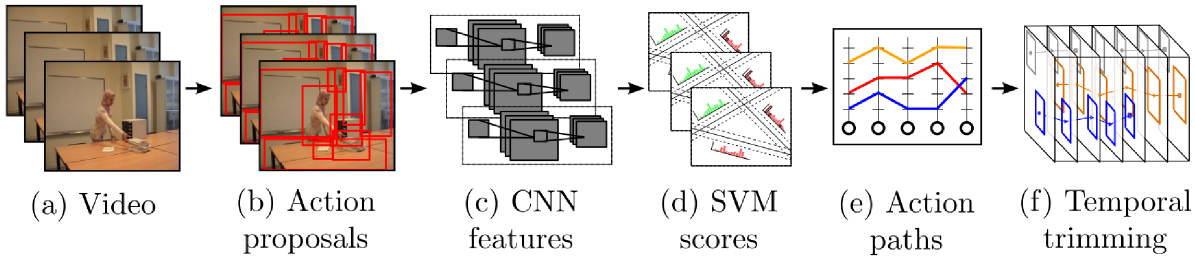
Overview of the proposed action detection pipeline. From the raw RGB video frames (a), region proposals are extracted (b), and passed to a fine-tuned CNN from which features are extracted (c). The features are used to score each region proposal (d), and from the scores, action paths are generated (e) and subsequently refined and trimmed in time (f).
